Learning Human Viewpoint Preferences from Sparsely Annotated Models
Computer Graphics Forum 2022
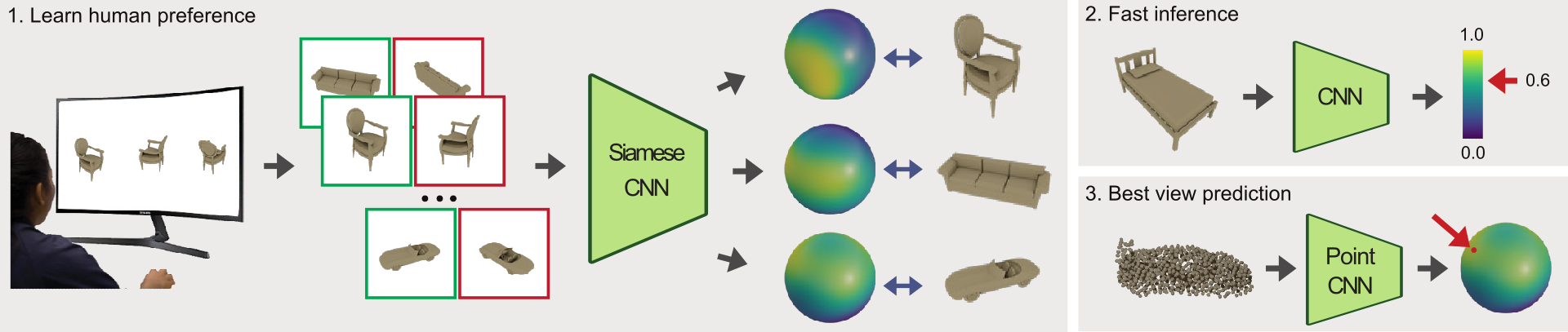
Abstract
View quality measures compute scores for given views and are used to determine an optimal view in viewpoint selection tasks. Unfortunately, despite the wide adoption of these measures, they are rather based on computational quantities, such as entropy, than human preferences. To instead tailor viewpoint measures towards humans, view quality measures need to be able to capture human viewpoint preferences. Therefore, we introduce a large-scale crowdsourced dataset, which contains 58k annotated viewpoints for 3220 ModelNet40 models. Based on this data, we derive a neural view quality measure abiding to human preferences. We further demonstrate that this view quality measure not only generalizes to models unseen during training, but also to unseen model categories. We are thus able to predict view qualities for single images, and directly predict human preferred viewpoints for 3D models by exploiting point-based learning technology, without requiring to generate intermediate images or sampling the view sphere. We will detail our data collection procedure, describe the data analysis and model training, and will evaluate the predictive quality of our trained viewpoint measure on unseen models and categories. To our knowledge, this is the first deep learning approach to predict a view quality measure solely based on human preferences.
BibTeX
@article{hartwig2022viewpoint,
title={Learning Human Viewpoint Preferences from Sparsely Annotated Models},
author={Hartwig, Sebastian and Schelling, Michael and van Onzenoodt, Christian and V{\'a}zquez, Pere-Pau and Hermosilla, Pedro and Ropinski, Timo},
year={2022},
journal={Computer Graphics Forum},
volume={41},
issue={3},
doi={10.1111/cgf.14613},
note={Major Revision from Eurographics 2022}
}